
Corruption erodes social trust more in democracies than in autocracies
Polymarket gamblers threaten to kill me over Iran missile story
The article reports on threats received by a journalist from gamblers who are unhappy with a story he wrote about Iran's missile program. The gamblers are allegedly trying to coerce the journalist into rewriting the story in order to influence the outcome of a bet placed on the online platform Polymarket.

Canada's bill C-22 mandates mass metadata surveillance
https://www.parl.ca/DocumentViewer/en/45-1/bill/C-22/first-r...
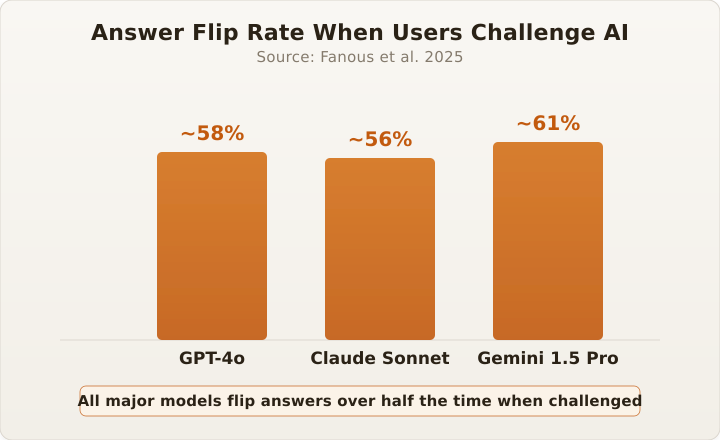
The "are you sure?" Problem: Why AI keeps changing its mind
The article explores the 'Are You Sure?' problem, where AI systems frequently change their outputs due to uncertainty and a lack of confidence in their own predictions. It discusses the importance of designing AI systems that can effectively communicate their level of certainty and handle situations where they are unsure.

How I write software with LLMs
The article discusses the author's approach to writing software using large language models (LLMs), highlighting the benefits of leveraging these models for tasks such as code generation, documentation, and problem-solving, while also addressing potential challenges and considerations when integrating LLMs into software development workflows.
The 49MB web page
The article discusses the importance of auditing news sources to verify their credibility and accuracy. It emphasizes the need for readers to critically evaluate the information they consume and encourages them to cross-check facts from multiple reliable sources.

Chrome DevTools MCP (2025)
The article discusses the new Multi-Client Debugging feature in Chrome DevTools, which allows developers to debug their browser sessions across multiple devices and browsers simultaneously, providing a more comprehensive debugging experience.
Nango (YC W23, API Access for Agents and Apps) Is Hiring

Home Assistant waters my plants
This article describes how to use Home Assistant, an open-source home automation platform, to automate the watering of houseplants. It covers setting up moisture sensors, creating automation rules, and integrating the system with smart plugs or irrigation controllers to water plants as needed.
Electric motor scaling laws and inertia in robot actuators
This article introduces the first part of a series on actuation, discussing the fundamental principles and components of various actuation systems, including electric motors, hydraulic and pneumatic actuators, and their applications in robotics and automation.
Six ingenious ways how Canon DSLRs used to illuminate their autofocus points
Stop Sloppypasta
What every computer scientist should know about floating-point arithmetic (1991) [pdf]
The article provides an overview of the IEEE 754 standard, which defines a binary floating-point representation for real numbers used in computer programming. It discusses the standard's design, key features, and its impact on numerical computations and programming practices.
LLM Architecture Gallery
The article presents an in-depth visual gallery showcasing the architectural designs and components of various large language models, highlighting the diversity of approaches and techniques employed by researchers and engineers in the field of natural language processing.

LLMs can be exhausting
The article discusses the challenges and exhaustion that can come with using large language models (LLMs), highlighting the cognitive load, time investment, and frustration experienced by the author when attempting to leverage these AI systems for various tasks.
Kona EV Hacking
This article discusses the recent advancements in electric vehicle (EV) technology, focusing on improvements in battery performance, charging infrastructure, and consumer adoption. It provides an overview of the current state of the EV market and the factors driving its growth, as well as the challenges and potential solutions for widespread EV adoption.

Why Are Viral Capsids Icosahedral?
The article explores the potential of viral capsids, the protein shells that encase viral genomes, as versatile nanoparticles for biomedical applications. It discusses their unique properties, such as their ability to self-assemble and encapsulate various payloads, and their promising uses in areas like drug delivery, vaccine development, and gene therapy.
Scientists discover a surprising way to quiet the anxious mind (2025)
Reviewing Large Changes with Jujutsu
Separating the Wayland compositor and window manager
This article discusses 'River Window Management', a window management technique that allows users to easily organize and navigate multiple windows on their computer desktop. It explains the key features and benefits of this approach, such as improved productivity and visual clarity.

The Accidental Room (2018)
The article explores the story behind the creation of the Accidental Room, a unique architectural feature in a building in San Francisco. It examines how an unintended space was transformed into a functional and valuable part of the structure, highlighting the unexpected ways buildings can evolve over time.
The Linux Programming Interface as a university course text
The article provides an overview of the 'The Linux Programming Interface' (TLPI), a comprehensive guide to the Linux and UNIX system programming interface. It covers a wide range of topics, including system calls, file I/O, signals, process management, and more, making it a valuable resource for developers working with the Linux operating system.
The emergence of print-on-demand Amazon paperback books
The article discusses the 'enshittification' of Amazon's Kindle platform, where the company has allegedly prioritized its own products and services over those of third-party sellers, resulting in a decline in the quality of the platform for customers and independent booksellers.

Glassworm is back: A new wave of invisible Unicode attacks hits repositories
The article discusses a security vulnerability, known as the 'Glassworm' attack, that targets Unicode characters in software packages like GitHub, npm, and Visual Studio Code. The vulnerability allows attackers to execute arbitrary code by exploiting how these platforms handle certain Unicode characters.
//go:fix inline and the source-level inliner
The Go blog post discusses the new 'inliner' tool, which can automatically inline functions in Go programs. This tool can improve performance by reducing function call overhead and enabling further compiler optimizations.

How far can you go with IX Route Servers only?
The article explores the capabilities and limitations of Internet Exchange (IX) route servers, discussing how far they can be used to influence routing decisions and the potential for abuse or misuse. It examines the impact of IX route servers on network traffic routing and the trade-offs between centralized control and distributed autonomy in Internet infrastructure.
Bus travel from Lima to Rio de Janeiro
The article describes a bus journey from Lima, Peru to Rio de Janeiro, Brazil, covering the challenges and experiences of traveling across South America by bus, including crossing borders, dealing with delays, and exploring the diverse landscapes along the way.

Lies I was told about collaborative editing, Part 2: Why we don't use Yjs
This article explores common misconceptions about software engineering, such as the belief that developers work alone, that coding is a linear process, and that technology is the only important aspect of the job. The author dispels these myths and emphasizes the importance of communication, collaboration, and problem-solving skills in the software development field.
What makes Intel Optane stand out (2023)
The article discusses Intel's Optane technology, which uses a unique memory architecture to offer faster performance and higher endurance compared to traditional storage solutions. It highlights Optane's ability to bridge the gap between memory and storage, providing a compelling solution for data-intensive applications.

A Visual Introduction to Machine Learning (2015)
This article provides a visual introduction to machine learning, explaining the core concepts of supervised learning, training data, and model predictions. It uses a simple example of predicting house prices to illustrate these fundamental machine learning principles.