
Palestinian boy, 12, describes how Israeli forces killed his family in car
The article discusses the potential risks and benefits of artificial intelligence (AI) as the technology becomes more advanced and prevalent in various industries. It explores concerns about AI's impact on jobs and the need for responsible development and regulation of the technology.

Meta’s renewed commitment to jemalloc
https://github.com/jemalloc/jemalloc

Leanstral: Open-source agent for trustworthy coding and formal proof engineering
Mistral AI has launched Leanstral, a new AI-powered platform that helps organizations streamline operations and decision-making. Leanstral combines natural language processing, predictive analytics, and workflow automation to optimize business processes and provide data-driven insights.
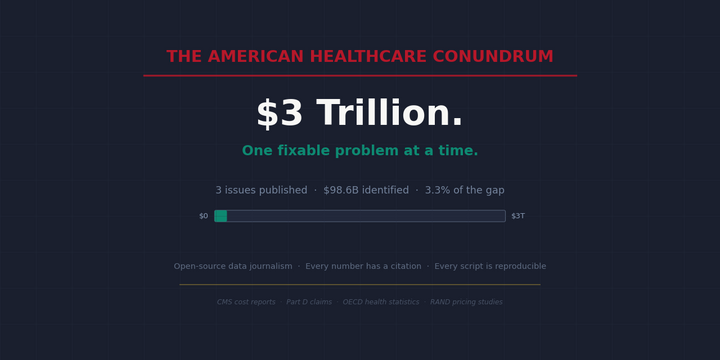
US commercial insurers pay 254% of Medicare for the same hospital procedures
The article explores the complexities and challenges of the American healthcare system, examining its high costs, limited accessibility, and ongoing debates surrounding potential reforms to address these issues.
Show HN: Claude Code skills that build complete Godot games
I’ve been working on this for about a year through four major rewrites. Godogen is a pipeline that takes a text prompt, designs the architecture, generates 2D/3D assets, writes the GDScript, and tests it visually. The output is a complete, playable Godot 4 project.
Getting LLMs to reliably generate functional games required solving three specific engineering bottlenecks:
1. The Training Data Scarcity: LLMs barely know GDScript. It has ~850 classes and a Python-like syntax that will happily let a model hallucinate Python idioms that fail to compile. To fix this, I built a custom reference system: a hand-written language spec, full API docs converted from Godot's XML source, and a quirks database for engine behaviors you can't learn from docs alone. Because 850 classes blow up the context window, the agent lazy-loads only the specific APIs it needs at runtime.
2. The Build-Time vs. Runtime State: Scenes are generated by headless scripts that build the node graph in memory and serialize it to .tscn files. This avoids the fragility of hand-editing Godot's serialization format. But it means certain engine features (like `@onready` or signal connections) aren't available at build time—they only exist when the game actually runs. Teaching the model which APIs are available at which phase — and that every node needs its owner set correctly or it silently vanishes on save — took careful prompting but paid off.
3. The Evaluation Loop: A coding agent is inherently biased toward its own output. To stop it from cheating, a separate Gemini Flash agent acts as visual QA. It sees only the rendered screenshots from the running engine—no code—and compares them against a generated reference image. It catches the visual bugs text analysis misses: z-fighting, floating objects, physics explosions, and grid-like placements that should be organic.
Architecturally, it runs as two Claude Code skills: an orchestrator that plans the pipeline, and a task executor that implements each piece in a `context: fork` window so mistakes and state don't accumulate.
Everything is open source: https://github.com/htdt/godogen
Demo video (real games, not cherry-picked screenshots): https://youtu.be/eUz19GROIpY
Blog post with the full story (all the wrong turns) coming soon. Happy to answer questions.

Nvidia Launches Vera CPU, Purpose-Built for Agentic AI
NVIDIA has announced the launch of Vera, a new CPU purpose-built for agentic AI, which is designed to enable intelligent agents to interact with users in more natural and contextual ways.

Apideck CLI – An AI-agent interface with much lower context consumption than MCP
This article discusses the MCP server, a CLI alternative that can help with issues like a 'server eating context window' problem. It provides an overview of the MCP server's features and how it can be used to improve developer workflows.

Beyond Meat CEO 'It's Just Not the Moment for Plant-Based Meat' After Rebrand
The article discusses the challenges faced by Beyond Meat, a leading plant-based meat producer, in maintaining its market position and brand relevance amidst increasing competition and shifting consumer preferences in the alternative protein market.

Teens sue xAI over Grok's pornographic images of them
The article explores the growing trend of people leaving their jobs to pursue entrepreneurship, driven by factors like the COVID-19 pandemic and the desire for more flexibility and control over their careers. It examines the opportunities and challenges faced by these 'Great Resignation' entrepreneurs as they navigate the risks and rewards of starting their own businesses.
Event Publisher enables event integration between Keycloak and OpenFGA
This article describes a Keycloak event publisher that integrates with OpenFGA, a flexible and scalable authorization service. The publisher allows Keycloak to publish authorization events to OpenFGA, enabling fine-grained access control and audit capabilities.
Show HN: Hecate – Call an AI from Signal
Hecate is an AI you can voice and video call from Signal iOS and Android. This works by installing Signal into an Android emulator and controlling the virtual camera and microphone. Tinfoil.sh is used for private inference.

CEO Asks ChatGPT to Void $250M Contract, Ignores Lawyers, Loses Terribly
The article describes a CEO who ignored legal advice and instead asked ChatGPT how to void a $250 million contract, resulting in a disastrous court loss for the company.

Show HN: Open-source, extract any brand's logos, colors, and assets from a URL
Hi everyone, I just open sourced OpenBrand - extract any brand's logos, colors, and assets from just a URL.
It's MIT licensed, open source, completely free. Try it out at openbrand.sh
It also comes with a free API and MCP server for you to use in your code or agents.
Why we built this: while building another product, we needed to pull in customers' brand images as custom backgrounds. It felt like a simple enough problem with no open source solution - so we built one.
China just approved world first commercial brain implant
China has approved the first commercial brain implant device, a significant milestone in the field of neural technology. The device, developed by a Chinese company, is intended to assist with neurological conditions and could pave the way for broader adoption of brain-computer interface technologies.

Amazon finds out AI programming isn't all it's cracked up to be
The article discusses Amazon's challenges in developing and implementing AI systems, highlighting the complexities and limitations of AI programming, despite the hype and expectations surrounding the technology.

Benjamin Netanyahu is struggling to prove he's not an AI clone
The article discusses the use of deepfake technology to create a fabricated video of former Israeli Prime Minister Benjamin Netanyahu making false claims about a conspiracy. It highlights the potential for this technology to be used for misinformation and the challenges in verifying the authenticity of online content.
Once (Again)
The article explores the author's frustrations with the tech industry's obsession with growth and constant change, arguing for a focus on sustainability, stability, and longevity instead. It highlights the need to prioritize thoughtful, measured progress over chasing the next big thing.

Tesla's Terafab chip fab ambitions ignore its lack of semiconductor experience
The article discusses Tesla's ambition to build its own semiconductor fabrication facility, known as 'Terafab', despite the company's lack of experience in the semiconductor industry. It highlights the challenges Tesla may face in realizing this ambitious project and the potential implications for the company's future operations.

Encyclopedia Britannica sues OpenAI for copyright and trademark infringement
Encyclopedia Britannica has filed a lawsuit against OpenAI, alleging copyright and trademark infringement related to the use of Britannica's content in OpenAI's language models and products. The lawsuit seeks to address the unauthorized use of Britannica's intellectual property in the development of AI systems.

How we Built Private Post-Training and Inference for Frontier Models
The article discusses the importance of private post-training for AI models, highlighting the benefits of protecting sensitive data and maintaining model integrity. It covers the risks of public model sharing and outlines strategies for secure private post-training to ensure the confidentiality and reliability of AI systems.